DMI – Corso di laurea magistrale in Informatica
Copyleft
![]() 2019 Giuseppe Scollo
2019 Giuseppe Scollo
![]()
la cartella codesign nell'archivio allegato è predisposta per ospitare lo sviluppo del progetto
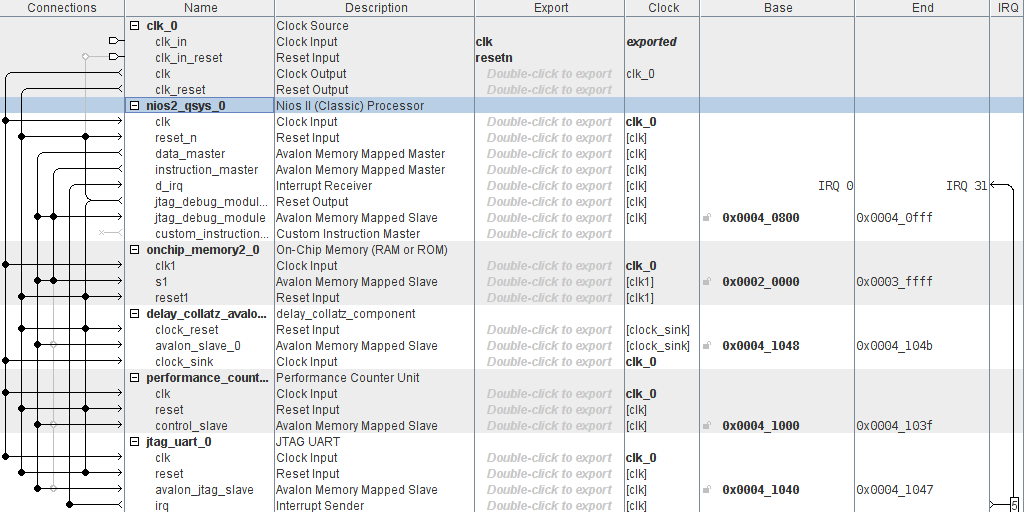
creato il progetto delay_collatz_codesign, con omonima entità top-level, si procede alla creazione del componente custom delay_collatz_interface
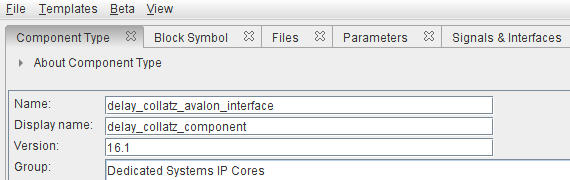
la definizione del nuovo tipo di componente è mostrata in figura
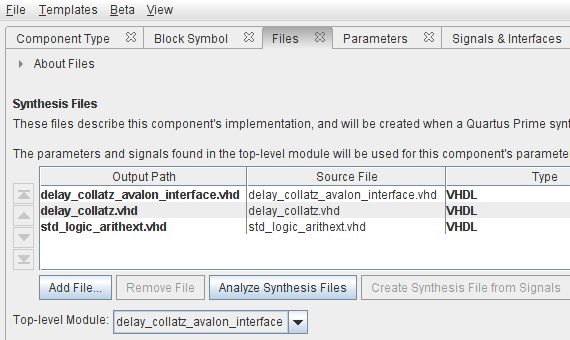
si procede quindi all'assegnazione dei file VHDL che descrivono il componente e alla loro analisi, come mostrato in figura
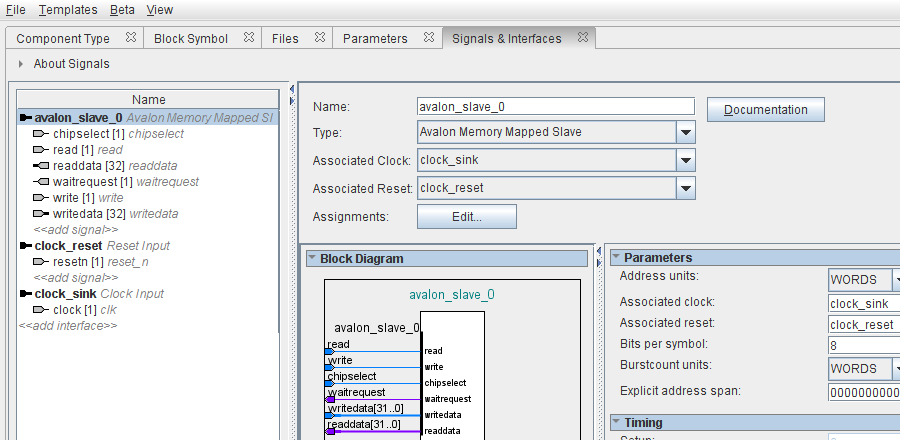
infine, si conclude la definizione del nuovo tipo di componente con la definizione delle sue interfacce Avalon e la collocazione dei segnali nelle interfacce appropriate, come illustrato in figura
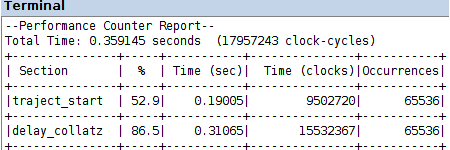
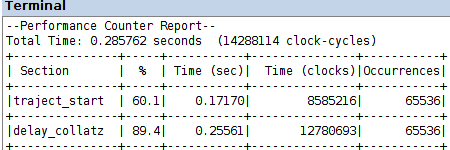
la compilazione, caricamento sulla FPGA ed esecuzione del programma delay_collatz_sequential_timing.c, nei due progetti codesign/amp_s e codesign/amp_s_o3 produce i Performance Counter Report in figura
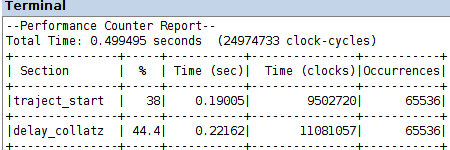
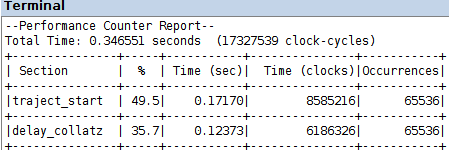
uno speed-up di un ordine di grandezza, rispetto al calcolo software nell'esercitazione 10, risulta dai dati di prestazione in quel caso, con gli stessi livelli di ottimizzazione
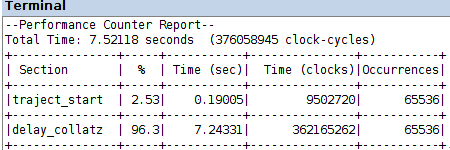
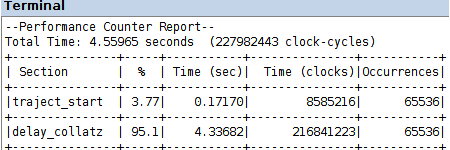
è lecito attendersi un ulteriore guadagno di prestazione dall'esecuzione non bloccante del calcolo nel componente hardware custom
dai Performance Counter Report che seguono, a confronto con i dati analoghi della realizzazione con tutto il calcolo in software, risulta uno speed-up 21x con ottimizzazione di default O1 e 16x con ottimizzazione O3; i corrispondenti valori dello speed-up con accelerazione bloccante sono 15x con O1 e 13x con O3