DMI – Graduate Course in Computer Science
Copyleft
![]() 2019 Giuseppe Scollo
2019 Giuseppe Scollo
![]()
folder codesign in the attached archive is preset to host the project development
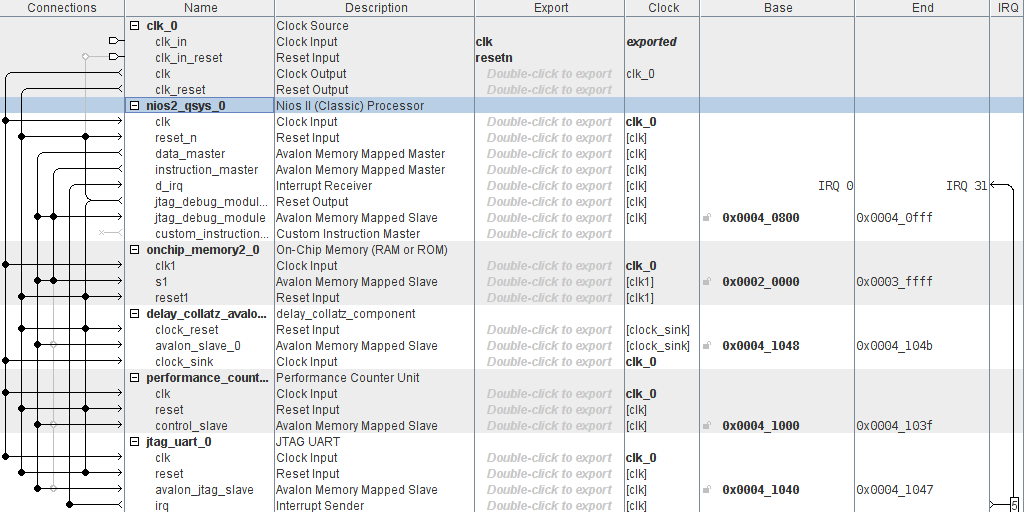
after creation of project delay_collatz_codesign, with top-level entity having the same name, the construction of the custom component delay_collatz_interface may proceed
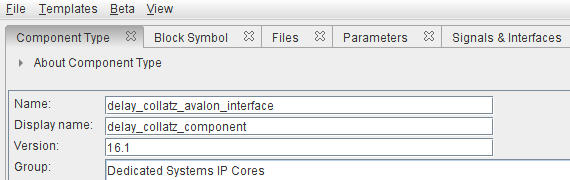
the new component type definition is shown in the figure
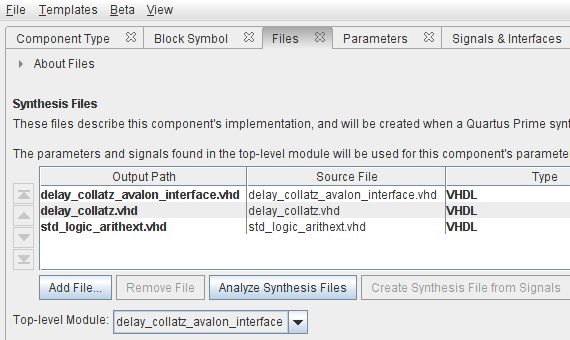
the next step is the assignment of VHDL files that describe the component and their analysis, as shown in the figure
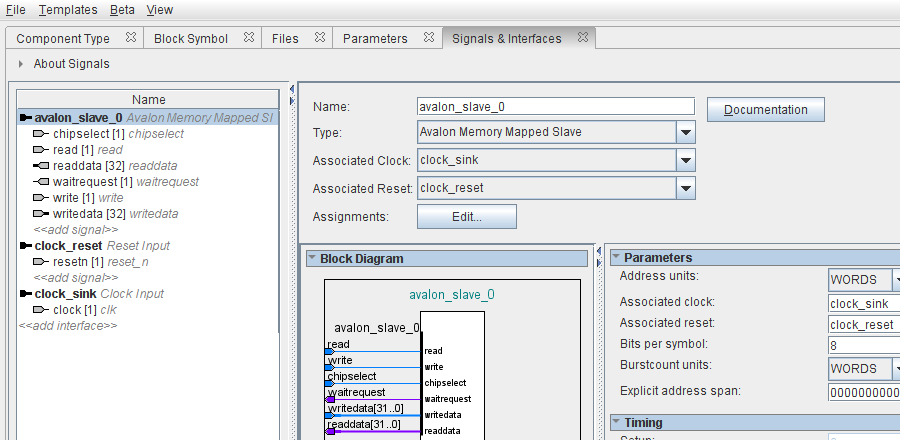
finally, the new component definition ends with the definition of its Avalon interfaces and placement of its signals under the appropriate interfaces, as shown in the figure
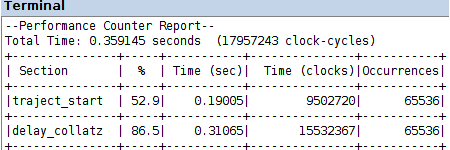
compilation, loading on the FPGA and execution of program delay_collatz_sequential_timing.c, in the two projects codesign/amp_s and codesign/amp_s_o3, produces the Performance Counter Reports in the figure
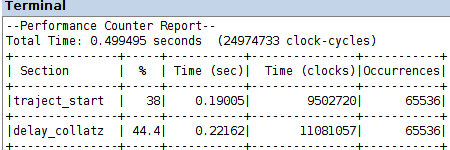
a speed-up by an order of magnitude, w.r.t. the software computation in lab tutorial 10, results from the performance data in that case, with the same optimization levels
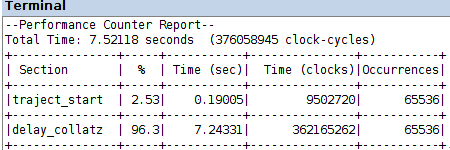
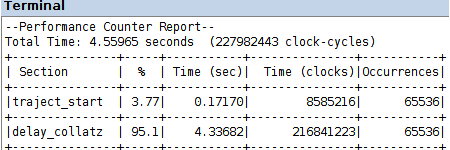
it is sensible to expect a further performance gain out of the nonblocking execution of the computation by the custom hardware
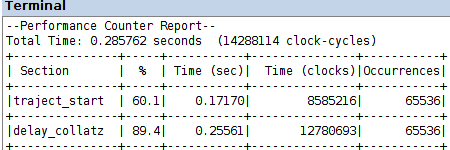
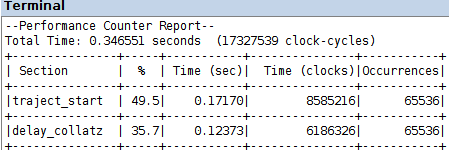
the comparison of the following Performance Counter Reports with the corresponding data for the implementation with all computation done in software, yields a 21x speed-up with default optimization O1 and a 16x speed-up with optimization O3; the corresponding speed-up values with blocking acceleration are 15x with O1 and 13x with O3