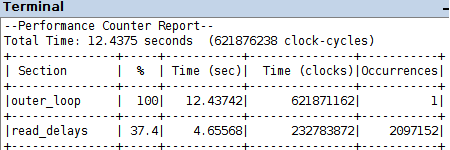
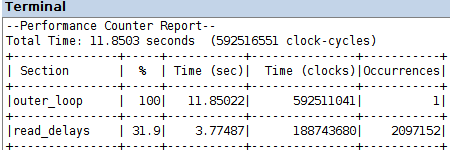
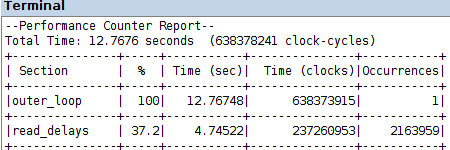
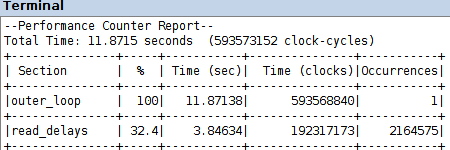
two-step production of the VHDL description of the multicore coprocessor:
-
1-core coprocessor with 64-bit input
-
2n-core coprocessor with
2n-bit status output
the respective sources
delay_collatz.vhd and
multicore_delay_collatz.vhd are available in folder
vhdl of the attached archive, as well as in the
VHDL/code/e12 folder of the reserved lab area
-
the 1-core coprocessor is derived from that of the
previous lab tutorial, by a straightforward modification of the
Gezel source and consequent variation of the VHDL output produced by the
fdlvhd translator
the coprocessor is endowed with the
core_select n-bit input, that encodes
the core which the I/O operation is addressed to, while the
done outputs of the individual cores are exposed as global status
in a 2n-bit parallel output port
-
the x0 and
delay data ports of the individual cores are deployed on internal
64*2n-bit and
16*2n-bit parallel signals,
respectively, wherein the decoding of
core_select selects the relevant part for the I/O operation
empty folders
delay_collatz,
mc_delay_collatz, and
mc_interface are meant to host compilation and simulation projects
for the two mentioned sources and the next one; folders with the same names
under
tests provide respective input files for simulation