DMI – Graduate Course in Computer Science
Copyleft
![]() 2018 Giuseppe Scollo
2018 Giuseppe Scollo
![]()
model elements to be mapped to software: actors, queues, firing rules
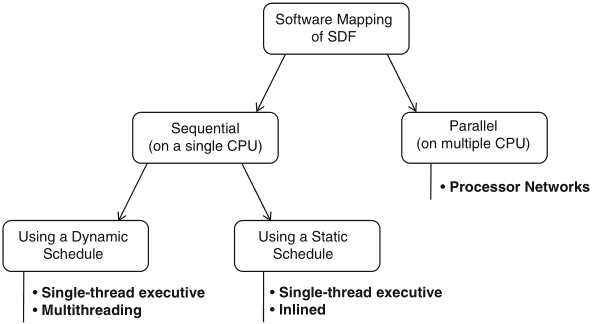
Schaumont, Figure 3.1 - Overview of possible approaches to map dataflow into software
parallel implementation, optimization of distribution of actors over the processors:
sequential implementation, options: scheduling, threading
FIFO queue, structure with:
it may be implemented as a circular array with two pointers to the access locations for the read and write operations, that are incremented mod N if the array size is N+1
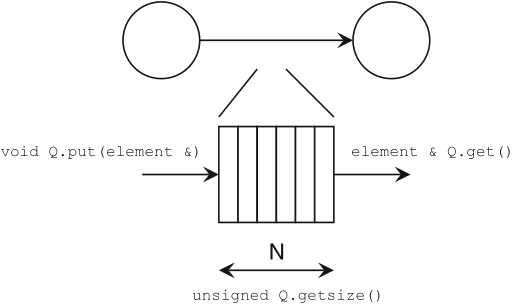
Schaumont, Figure 3.2 - A software queue
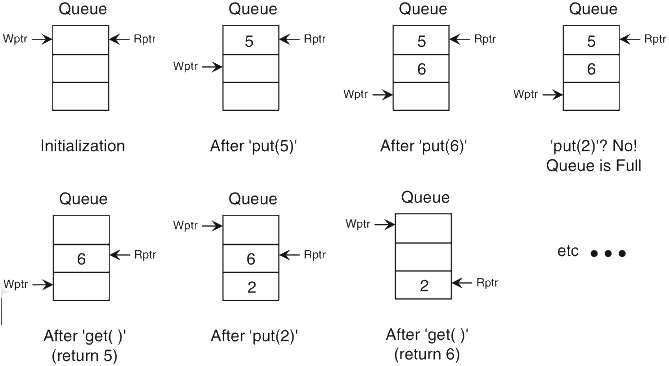
Schaumont, Figure 3.3 - Operation of the circular queue
a C function, parameterized with a data structure to support I/O on the FIFO queues
a first, elementary example of FSM with datapath (FSMD):
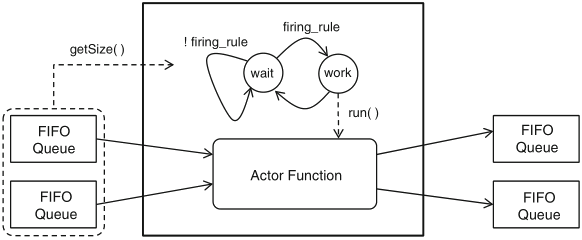
Schaumont, Figure 3.4 - Software implementation of the datafow actor
a dynamic system scheduler instantiates and initializes actors and queues, then it invokes the actors–say, in a round robin fashion:
void main() {
fifo_t q1, q2;
actorio_t fft2_io = {{&q1}, {&q2}};
..
init_fifo(&q1);
init_fifo(&q2);
..
while (1) {
fft2_actor(&fft2_io);
// .. call other actors
}
}

Schaumont, Figure 3.5a - A graph which will simulate under a single rate system schedule

Schaumont, Figure 3.5b - A graph which will cause extra tokens under a single rate schedule
system schedule
void main() {
..
while (1) {
src_actor(&src_io);
snk_actor(&snk_io);
}
}
a problem is apparent with the example in the second figure
solution 1: adjust system schedule
void main() {
..
while (1) {
src_actor(&src_io);
snk_actor(&snk_io);
snk_actor(&snk_io);
}
}
solution 2: adjust actor snk code
void snk_actor(actorio_t *g) {
int r1, r2;
while ((fifo_size(g->in[0]) > 0)) {
r1 = get_fifo(g->in[0]);
... // do processing
}
}
the fast (discrete) Fourier transform is widely used in signal processing
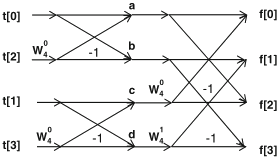
Schaumont, Figure 3.6a - Flow diagram for a four-point Fast Fourier Transform
a = t[0] + W(0,4) * t[2] = t[0] + t[2]
b = t[0] - W(0,4) * t[2] = t[0] - t[2]
c = t[1] + W(0,4) * t[3] = t[1] + t[3]
d = t[1] - W(0,4) * t[3] = t[1] - t[3]
f[0] = a + W(0,4) * c = a + c
f[1] = b + W(1,4) * d = b - j.d
f[2] = a - W(0,4) * c = a - c
f[3] = b - W(1,4) * d = b + j.d
an SDF model for the magnitude computation in the frequency domain:

Schaumont, Figure 3.7 - Synchronous dataflow diagram for a four-point Fast Fourier Transform
with multithreading, dynamic scheduling is implemented by assigning each actor its own thread of execution
often: round-robin scheduler + solution 2 seen earlier
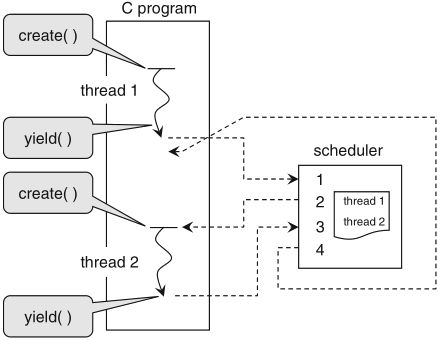
Schaumont, Figure 3.8 - Example of cooperative multi-threading
QuickThreads library functions:
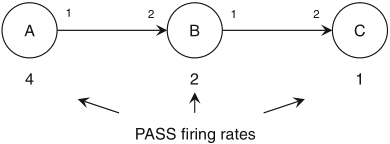
static scheduling allows optimization of a software implementation in three respects:
example:
while(1) {
// call A four times
A(); A(); A(); A();
// call B two times
B(); B();
// call C one time
C();
}
Schaumont, Figure 3.9 - System schedule for a multirate SDF graph
the static schedule in the figure is a PASS, yet it is not optimal for the minimization of the capacity of the queues: the firing sequence (A, A, B, A, A, B, C) is optimal