tali leggi possono rendere più spedita
la ricerca dei CR, che tuttavia richiede una
esplorazione esaustiva
dello spazio di ricerca
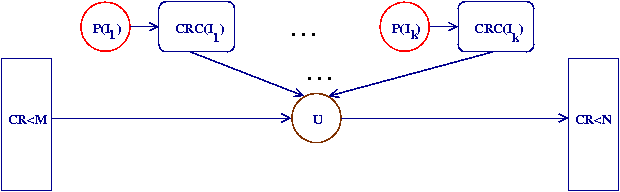
questa può essere facilmente parallelizzata partizionando
lo spazio di ricerca in intervalli disgiunti, esplorati da
istanze indipendenti
di un programma di ricerca, opportunamente parametrizzato,
ciascuna delle quali produca un insieme di
candidati CR
minimi elementi di ciascuna classe di ritardo nell'intervallo dato
una piccola accelerazione del calcolo del ritardo si ottiene rimpiazzando
la funzione f con
T,
definita come f sui numeri pari, mentre
per xdispari
si ha:
Tx = (3x + 1)/2 = x + ⌈x/2⌉
chiaramente, se la T-traiettoria da
x a 1 ha
A applicazioni di questa regola e
E applicazioni del dimezzamento dei pari,
allora
D(x) = 2A + E
l'interesse a T deriva dall'esistenza di
una permutazione dei residui (mod 2k),
definita dal k-prefisso del cosiddetto
vettore di parità delle
T-traiettorie,
cioè la sequenza binaria, dipendente da x,
definita da
vi(x)
= (T ix) mod 2
il k-prefisso di
vi(x)
dipende solo da
x (mod 2k)
si possono dunque definire 2k composizioni
distinte di k passi di applicazione di T, e decidere quale di esse si debba
applicare a x solo in base al valore del residuo
x (mod 2k): ne risulta una notevole accelerazione del calcolo, mediante tecniche di
pre-processing
sebbene si adoperino macchine a 64 bit, una parola di memoria non basta
alla rappresentazione di molti dei valori attraversati da traiettorie
con origine nell'attuale intervallo di ricerca
buona notizia: finché l'origine sta sotto
262,
due parole bastano
questo fatto è una conseguenza dei risultati più recenti nella
ricerca dei Path Records, v. il
sito di Eric Roosendaal
per approfondimenti in proposito
l'aritmetica delle traiettorie 3x+1 è relativamente semplice da
realizzare per numeri rappresentati da 2 parole, quando si calcola
il ritardo procedendo un passo alla volta nella traiettoria
diventa più complessa quando si adotta la tecnica di accelerazione
controllata qui accennata
buona parte dell'aumento di complessità può però essere affrontato
in sede di pre-elaborazione delle costanti in gioco, dunque senza
compromettere le prestazioni del programma di ricerca dei CR
un accorgimento essenziale, v.
(Leuvens & Vermeulen, 1992),
consiste nel formulare i composti
T kx
in tal modo che nessun valore intermedio, nel calcolo dell'espressione,
ne superi il valore finale
la formulazione impiegata nel software attualmente in uso soddisfa questo
requisito, e fornisce una definizione induttiva (in k), dei coefficienti
che intervengono nell'espressione, che ne permette l'impiego in sede di
pre-elaborazione; v. (Scollo, 2008) per dettagli
Scollo (2008) :
Looking for Class Records in the 3x+1 Problem
by means of the COMETA Grid Infrastructure, Grid Open Days at the University of Palermo,
Palermo (Italy), 6-7 December 2007, in press, 2008.
CR3x+1PAr2008.pdf